Table of Contents
Source code contributed to Expresso should follow certain guidelines. Contributors should follow the Sun Java Coding Conventions, except fot the following exceptions and clarifications:
License
The Jcorporate Apache Style Software License must be placed at the top of each java source file.
Indentation
Four spaces (no tabs) should be used for indentation.
Line Length
Avoid lines longer than 120 characters.
In order successfully modify the EDG you need to learn about
DocBook. DocBook consists of two parts:
The Docbook DTD ; the grammar rules contains in a Document Type Definition file.
The Docbook XSL stylesheets - extensible mark-up stylesheet language files, special template files that describe how to convert raw XML to printable format for presentation e.g. HTML for the web browsers.
Since Docbook has it's roots in SGML (Standard General Mark-up Language). SGML is a pre-cursor to XML that originated in the 1970s. You will see many SGML references on docbook websites, but you can safely ignore them. In order to modify the developer guide you have to located. It can be found in the web container under `${CONTAINER_HOME}/webapps/expresso/expresso/doc/edg/edg.xml'.
The file is a DocBook XML file in order to convert the raw data to a usual output medium you simply have to locate the the appropriate stylesheets. They exist for:
HTML - hypertext mark-up language
FOP - formatted object protocol (e.g Adobe PDF)
RTF - Rich Text Format
XHTML - Extensible Mark-up well formed HTML
HTML-Help - A Microsoft Windows Html Help file (.chm)
Most people are interested in converting DocBook XML to HTML in order to create the EDG as an HTML file. Here is the line in the build.xml file that does that execution, it should help you run it from the command line:
<java classname="org.apache.xalan.xslt.Process"
classpath="${buildclasspath}" maxmemory="64m"
failonerror="true" fork="true">
<arg line="-IN expresso/doc/edg/edg.xml
-xsl expresso/doc/edg/docbook-xsl/html/docbook.xsl
-OUT expresso/doc/edg/edg.html"/>
</java>
Essentially one uses the commands above to generate other types of document such as Rich Text Format or Portable Document Format. Here are some other links of interest for dealing with DocBook:
In the CVS repository change to the EDG directory. This should be the directory that contains `edg.xml'. NB: The example assumes a compatible Linux or UNIX operating system. The CVS repository is stored in Mr Tony Blair's home directory at `/home/blairt/proj/expresso'. So we change to the EDG directory.
% cd /home/blairt/proj/expresso/expresso-web/expresso/doc/edg
Use a XML Stylesheet Langauge Template (XSLT) engine to transform the DocBook XML to a well formed HTML document `edg.html'. In this example we will use Apache's Xalan to perform this. The stylesheets are located in subdirectory `docbook-xsl/html' of the EDG directory. You may also need to set the classpath to find the Xalan JAR file.
% java -classpath /home/blairt/proj/lib/WEB-INF/lib/xalan.jar:$CLASSPATH \ org.apache.xalan.xslt.Process \ -IN edg.xml -xsl \ docbook-xsl/html/docbook.xsl \ -OUT edg.html
In order save a lot of typing I would put the above command in a Shell script. Here is an example of a such a quick-fix shell script
#!/bin/sh
# Shell script `Convert-EDG-Xml2Html'
# Peter Pilgrim Mon Sep 30 17:35:50 BST 2002
myname=`basename $0`
JAVA_CMD=java
XALAN_JAR=${HOME}/proj/lib/WEB-INF/lib/xalan.jar
echo "Transforming Expresso Developer Guide from XML to HTML."
cd ${HOME}/proj/expresso/expresso-web/expresso/doc/edg
(set -x verbose; ${JAVA_CMD} -classpath ${XALAN_JAR}:${CLASSPATH} \
org.apache.xalan.xslt.Process \
-IN edg.xml -xsl \
docbook-xsl/html/docbook.xsl \
-OUT edg.html )
status=$?
if [ $status -ne 0 ]; then
echo "$myname: XSLT Transformation failed (error status:$status)" 1>&2
exit 1
fi
# End-of-script
A unified diff patch is the format that is used by Linux Kernel developers. This is a special type that preserves the differences between source files. On UNIX and Linux a context diff file is created with the diff command.
% diff -u acme.java.org acme.java > acme.java.diff.peter
Here a sensible developer backed up the original source and then made some modifications to a copy file. He, then, created a patch, a unified diff file. He sents the patch files to the lead developer who if she is also running a UNIX system can applied the patch. The lead developer will apply the patch like this:
% patch -p0 < acme.java.diff.peter
Often a contributor has made a lot of changes across many files. On UNIX system a shell script can help reduce the work of creating patches. Here is a shell script that helps to generate unified diff patch. This scripts searches for files that suffixed by a particular extension, say `.orig'. The script creates patches, unified diffs, for each of these files automatically.
#!/bin/sh
# Program ``generate-patch'' Mon Sep 30 02:08:40 BST 2002
SysWarn ()
{
echo "$myname: *WARNING* : $*" 1>&2
}
SysError ()
{
echo "$myname: *ERROR* : $*" 1>&2
exit 1
}
myname=`basename $0`
if [ -z $1 -o -z $2 ]; then
cat <<-XEOF
USAGE: $myname <DIRECTORY> <DIFF-EXTENSION>
Generates a software patch for any development application.
This program prints the diff to the standard output.
e.g.
% $myname com/xenonsoft .orig
XEOF
fi
directory=$1
extension=$2
if [ ! -d $directory ]; then
SysError "no such directory: \`$directory'"
fi
if [ ! -r $directory ]; then
SysError "cannot read directory: \`$directory'"
fi
find $directory \( -name "*$extension" -o -name "*.$extension" \) -type f -print |
while read file1
do
# e.g file1=acme.java.orig => file2=acme.java
file2=`echo $file1 | sed 's!'$extension'$!!'`
if [ ! -f $file2 ];then
file2=`echo $file1 | sed 's!'\.$extension'$!!'`
fi
if [ ! -f $file2 ]; then
SysWarn "cannot find missing patch file:\`$file2\'"
else
# Create unified diff patch
diff -u $file1 $file2
fi
done
# End-of-script
The script is typically used like this. I am assuming UNIX again.
% cd /home/blairt/proj/expresso % generate-patch \ expresso-web/WEB-INF/src/com/jcorporate/core/dbobj \ .orig > dbobj.diff.peterp-20020930
If you have a working CVS repository on your system then you can edit the diff line in the script file, so that you get difference up-to-date and accurate from CVS. Simply replace the the diff with the following
cvs diff -u $file2
The information in the section is distilled at Jakarta Apache Bug Submission web page
Due to natural testing habits, Expresso works best with the databases the core development team works with the most. These tend to be:
Other databases that are frequently used by community members but may not have up to date documentation or might have some testing issues are:
HSQL (Formerly Hypersonic) This database gets quite a bit more testing than the others because Expresso is distributed with this database. However, since it isn't used during the normal development process, it isn't as thoroughly tested as the ones listed above.
So what do you do if Expresso doesn't directly support your native database? Not a problem! The following section will help guide you through the process of how to port Expresso to your database. We will include sections on how to get a quick "Up And Running" and then later show you how to test the system so that you know that your configuration works for all Expresso-supported data types.
Before we proceed, let us encourage you that porting to a database is seldom a really painful process. Perhaps a field will need to be renamed, or perhaps the CREATE TABLE statement will have to be slightly modified, but in most cases, you won't have to modify Expresso's code at all.
Note
If you get another database up and running, please please please please (Have we made it clear?) submit your patches and or supporting configuration file to the community! You will save yourself A LOT of work in the long run as contributing database documentation will get more people using that database, and thus more eyes on the code to spot bugs.
[End "Soap Box"]
The database porting process can, in a short diagram, be summed up like this:
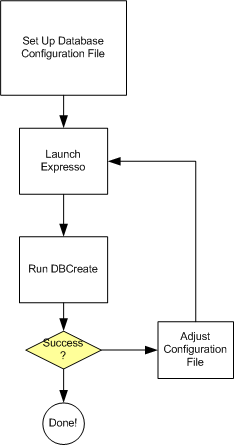
You will need to create a skeletal jdbc entry in the database to get started. To find the entries you want, take a look at the database JDBC documentation. First off, a sample of a skeletal configuration:
<context name="hypersonic" active="true"> <description>Hypersonic Database</description> <jdbc driver="org.hsqldb.jdbcDriver" url="jdbc:hsqldb:%web-app%WEB-INF/db/default/default" connectFormat="3" login="sa" password="" cache="y" createTableIndicies="true" limitationPosition="" escapeHandler="com.jcorporate.expresso.core.db.DoubleQuoteEscapeHandler" skipText="true"/> <!-- Type mappings eventually go here --> <type-mapping> <java-type>LONGVARCHAR</java-type> <db-type>LONGVARCHAR</db-type> </type-mapping> <images>%context%/%expresso-dir%/images</images> <startJobHandler>n</startJobHandler> <showStackTrace>y</showStackTrace> <mailDebug>n</mailDebug> </context>
Most of the items can be left as is, but the key would be the entries for the <jdbc> tag. Here is where you can get that information from your documentation.
Table A.1. JDBC Attributes
| Attribute | What To Set It To | |
|---|---|---|
| driver | Look at your driver docs. The value in Class.forName("database driver class"); will be what you want to set this value to. | |
| url | Look for the URL the database driver is connecting to. Put that value here. | |
| connectFormat | Most databases will work well with "1" Try other varieties if you have connection issues. | |
| login | Depends on your database. The connection account Expresso should use for the database | |
| password | Depends on your database. The connection password Expresso should use for the database. | |
| cache | Usually set to "true" | |
| createTableIndicies | Set to "true" unless your database has weird index creation routines and DBCreate fails on index creation. In this case you'll need to create database indicies manually. | |
| limitationPosition | Leave Blank | |
| escapeHandler | In most cases set to: com.jcorporate.expresso.core.db.DoubleQuoteEscapeHandler. This is for filtering the SQL strings against sql injection attacks so characters like "'" will work in a database query properly. If you have trouble with database values, you MIGHT want to set it to: com.jcorporate.expresso.core.db.DefaultEscapeHandler | |
| skipText | Leave to true. What this does is exclude 'text' (not varchar) fields from searches. This is best for database efficiency even if your database does support searches in long text fields. |
Now launch your app server. Go to the expresso home page (expresso/frame.jsp), click on "Setup" and run "Create and Verify Database" this is otherwise known as DBCreate. Have all boxes checked and run it.
If DBCreate fails, take a close look at the error message. In particular, take a look at the generated SQL Expresso claims to have attempted to execute against the database. Once you isolate the issue that is causing the problems, take a look at the solutions listed below.
Table A.2. DBCreate Failure Issues
| Symptoms | Cause | Solution |
|---|---|---|
| Weird database types. Example: Identity instead of Integer | Incorrect Database Type Mappings | Add a new database type mapping to the config file. |
| Invalid Primary Key Generation Statements. | Expresso is generating incorrect primary keys that your database doesn't understand. | Modify TableCreator code to create statements compatible with your database. |
| Create statement is failing, everything looks ok in the statement. | Check a list for your database of reserved words. Chances are either the table name or the field names are reserved for your database | Rename the offending fields or table name to something more innocuous and submit a patch to the Expresso community. |
Most of the time you will need to simply adjust the type mappings on your database. To add an entry, take a look at the DBObject class that the create is failing on. Find out what type it is supposed to be and add a line to your config mapping that will look similar to this:
<type-mapping> <java-type>TINYINT</java-type> <db-type>SMALLINT</db-type> </type-mapping>
On rare occasions, you might have to modify source code. The following are the most typical scenarios that may happen:
Reserved Table or Field Name When porting to a new database. Often table names or field names will be reserved keywords in your database. If it is, you will have to rename either the table or the field name. Do this via a global search and replace. Submit the changes to the Expresso community so that we can have the changes included in the next major revision. To deemphasize the impact this may have, the best practice in Expresso is to use string constants in naming database field names. However, there are several areas where this switchover has not yet been completed.
Invalid Primary Key Generation There have been several databases that have unique ways of generating primary key statements. The class com.jcorporate.expresso.core.db.TableCreator is the location where all this code is done. To patch it for your particular database, add a new if(drivername == "com.yourdatabase.Driver") { [create primary key] } type of statement.
Now that you have DBCreate working, you're probably about 80% of the way to a completely correct configuration. Expresso itself doesn't use all the supported database types in its tables. Therefore, you'll want to run some of the more thorough tests to make sure that your configuration is fully working with your database.
To do this, set up a Unit Test run. To do this, locate the article about Unit Testing in the Expresso documentation bundle. The test you're going to run is com.jcorporate.expresso.core.dbobj.tests.DBObjectTest. Run the test, (The unit test has a main[] function, so you can just "Run" the class and thus perform the test) and perform the same process you did as in the quick start. Once you have all the database unit tests passing you have will have successfully mapped all supported Expresso unit test types!
The following section is optional. Your database may or may not support Large Objects (LOBS). So the following test is optional depending on your needs.
Set up another unit test just like you did in the previous DBObjectTest. This time run the class com.jcorporate.expresso.core.dataobjects.jdbc.tests.LobFieldTest. This will get you an idea if the database at least supports some sort of Large Objects.
Note
Once this passes, your database still might not support LOBs directly! Test your database by trying to insert an object the size of the maximum object size you wish to use in your deployment. Make sure your app won't run out of memory inserting it and make sure the database driver doesn't corrupt the LOB in any way. You may need custom code at this point if your tests fail. We did such code for the Oracle database. Take a look at com.jcorporate.expresso.core.dataobjects.jdbc.LOBField to see if you can modify it to support your database. Again, submit any patches to us for inclusion in later releases!
At this point, you have reasonable assurance that your database configuration file is working correctly. Please submit your new config file With passwords, usernames, and machine names stripped to the Expresso community for inclusion in the future documentation.
The following persons have contributed their time to this chapter:
Mike Rimov
Mike Traum (JGroup Expert)
Note
Was this EDG documentation helpful? Do you wish to express your appreciation for the time expended over years developing the EDG doc? We now accept and appreciate monetary donations. Your support will keep the EDG doc alive and current. Please click the Donate button and enter ANY amount you think the EDG doc is worth. In appreciation of a $35+ donation, we'll give you a subscription service by emailing you notifications of doc updates; and donations $75+ will also receive an Expresso T-shirt. All online donation forms are SSL secured and payment can be made via Credit Card or your Paypal account. Thank you in advance.
